Paper: arXiv
Authors: Ziteng Wang, Jianfei Chen, Jun Zhu
Overview
Classical MoE with softmax and top-K gating mechanism suffer from non-differentiability (due to top-K being a non-differentiable function) which makes them difficult to train. This paper completely replaces softmax and top-K with ReLU. A router using ReLU selects the experts. ReLU naturally zeros all the negative activations, and the experts corresponsing to positive activations are chosen for the forward pass (explained more formally later). Authors use clever load balancing and sparsity loss to make sure the router has desired properties.
Preliminaries
Throughout this post: , where is the total number of tokens (context length) and is the dimension of residual stream (d_model)
MoE
: This represents the output vector at layer for the token at position . It’s the result of the MoE layer’s computation.
: This is the input vector to the MoE layer at layer l for the token at position t.
: The subscript indicates the routing weight or importance assigned by the router to the e-th expert for the current input . The router essentially determines to what extent each expert should contribute to the final output.
: This represents the e-th Feed-Forward Network (FFN) expert. is the intermediate size of expert. Usually 4 * .
Top-K Routing
In Top-K routing the router is defined as:
and retains the top values while setting the rest to zero.
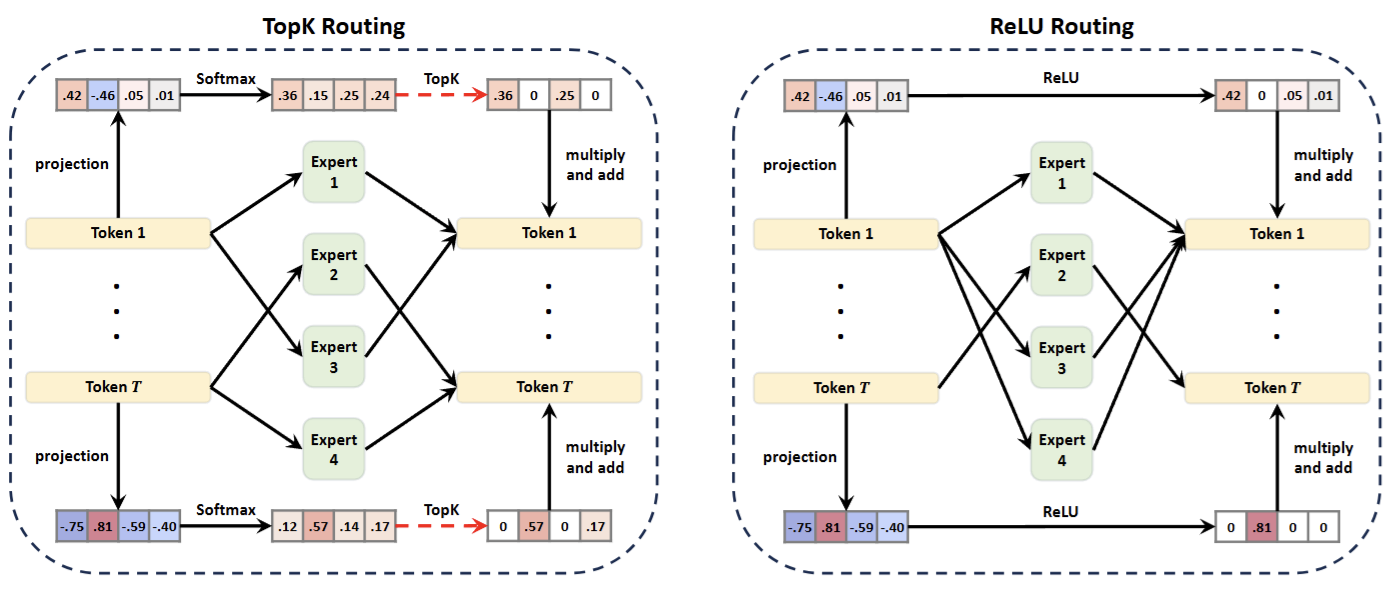
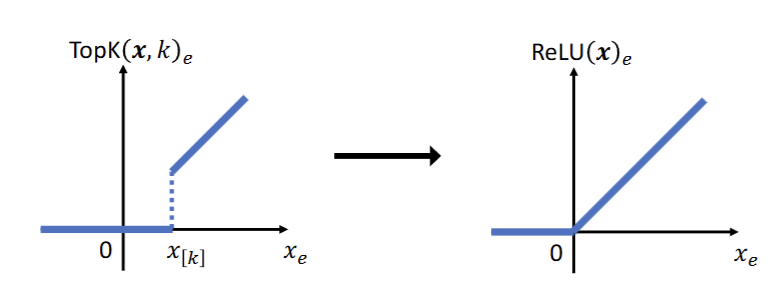
But the problem with top-K function is that it is clearly discontinuous with jump discontuity at the largest value as seen in the figure. The jump discontinuity can be fully eliminated with a ReLU and experts transition between being active and inactive at .
ReMoE
ReLU routing function is defined as:
, with being the sparsity where k is the number of active experts.
In regular the Softmax outputs sum to 1, representing the probabilities of selecting each expert. Only the highest are retained and the rest are eliminated. But in , naturally acts as a gate at the point zero. The outputs of routers represent the weights assigned to each expert, which can include 0. allows the router to learn which experts to activate (i.e., when to produce 0s) in a fully differentiable manner.
Another key difference between them is that is always forced to choose experts, but can dynamically choose the number of experts as it’s not hard coded. This would possibly allow more compute to be dedicated to tokens which are difficult to process.
But the key question is how do we regulate the sparsity and load balance between experts?
Controlling Sparsity via regularization
To regulate sparsity and achieve the desired sparsity of , authors introduce a regularization loss along with the language modeling loss.
where,
and are hyperparameters chosen at the beginning and from then is adaptively changed at every step.
denotes average sparsity of all router outputs at step ,
The key intuition being, is the total number of experts that can be active for a forward pass, it’s the maximum possible number.
is the actual number of active experts in the forward pass.
gives us the ratio of . So denotes the average sparsity.
Back to ,
is positive if desired sparsity is lesser than (there are more active experts than desired). And is increased by a factor of .
Similarly, if is negative if desired sparsity is greater than (there are less experts active than desired). So is reduced by a factor of .
The regularization term uses the -norm:
With this , we can control the sparsity around the desired level of . A key implication of this is that, on average, ReMoE ensures tokens are routed to experts across different layers, tokens maintaining same FLOPs as regular . So the model has complete control of how many experts to activate as long as the number of experts activated on average are within the desired level. We get to see the number of experts active across different layers varies.
Integrating Load Balancing into Regularization
To address load balancing, authors modify the loss term introduced above.
is non-differentiable and represents the average activation ratio of expert in layer ,relative to the desired ratio . This mechanism penalizes experts receiving more tokens by driving their router outputs toward zero more rapidly.
Three Stages of training of ReMoE
Authors observe three stages during training.
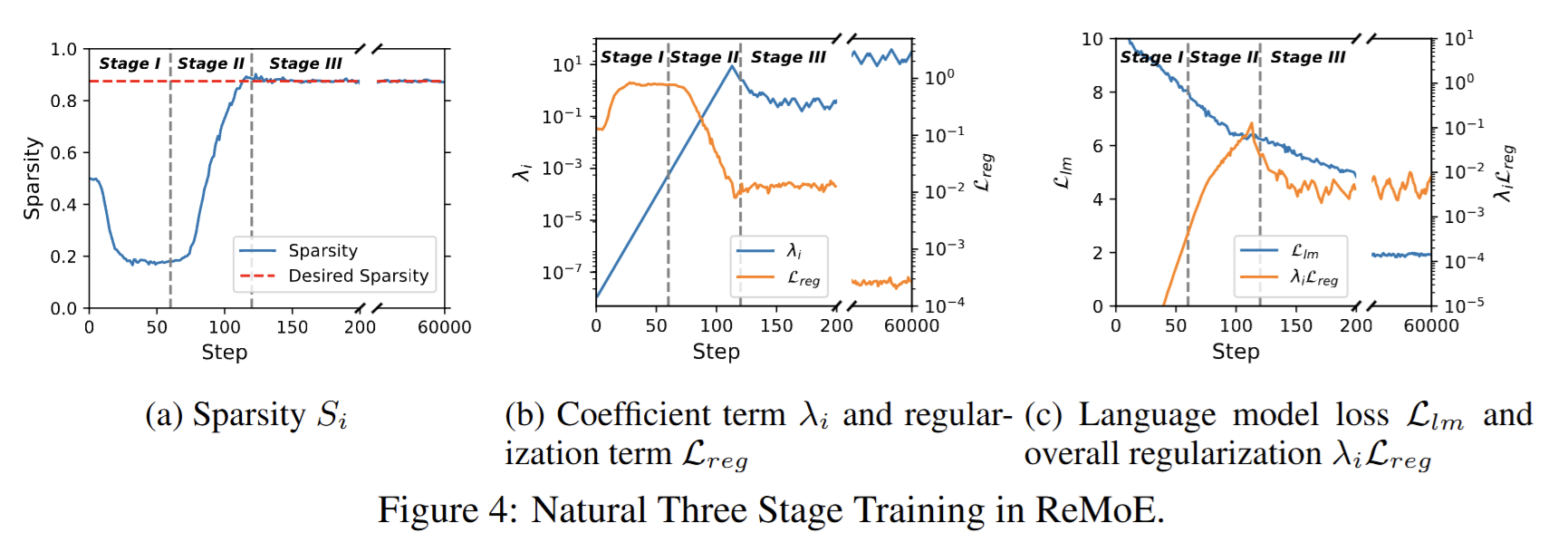
The first stage is the warm-up stage, or the dense stage. During this stage, is small, while is large and decreases rapidly. Training at this stage is nearly equivalent to training its dense counterpart with the same total number of parameters. Each expert processes more than half of the tokens, allowing the experts to diversify from their random initializations.
The second stage is the sparsifying stage, or the dense to sparse stage. At this point, the sparse regularization term becomes significant, causing the routers to activate fewer experts. This forces the experts to become more diverse without causing an increase in
The third stage is the stable stage, or the sparse stage. In this phase, the sparsity stabilizes at the preset target. During this stage, is optimized while being softly guided along the sparse subspace by . Both and change very slowly, with gradually decreasing and gradually increasing. However, the overall regularization term, , remains relatively constant.
Results
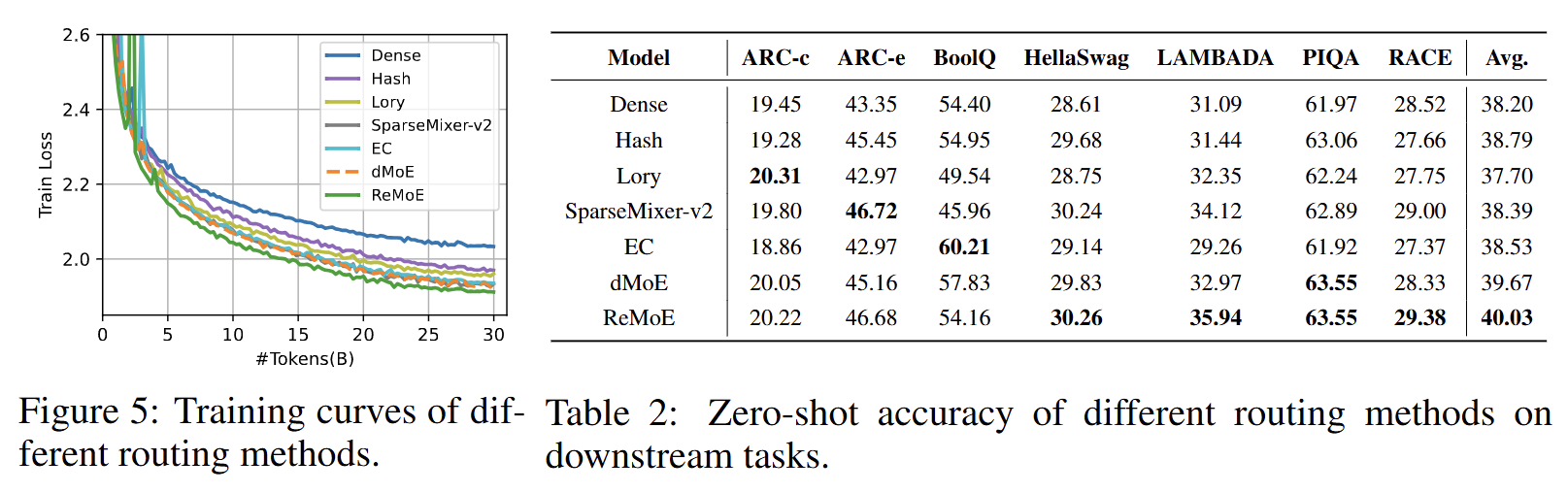
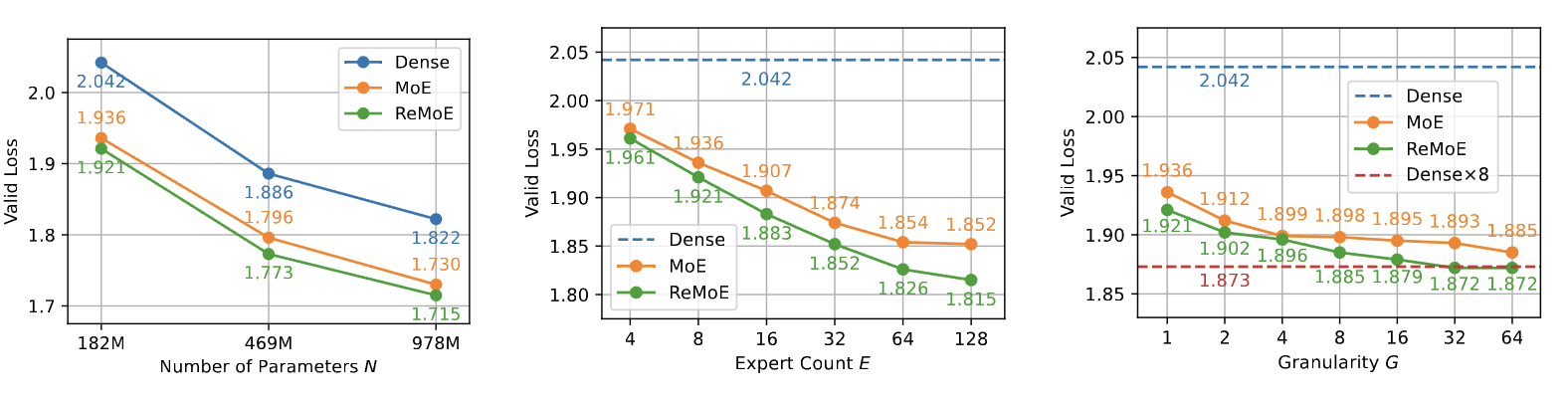
The authors perform extensive testing. They provide many details and it should be fairly easy to replicate.
Discussion
Dynamic expert allocation
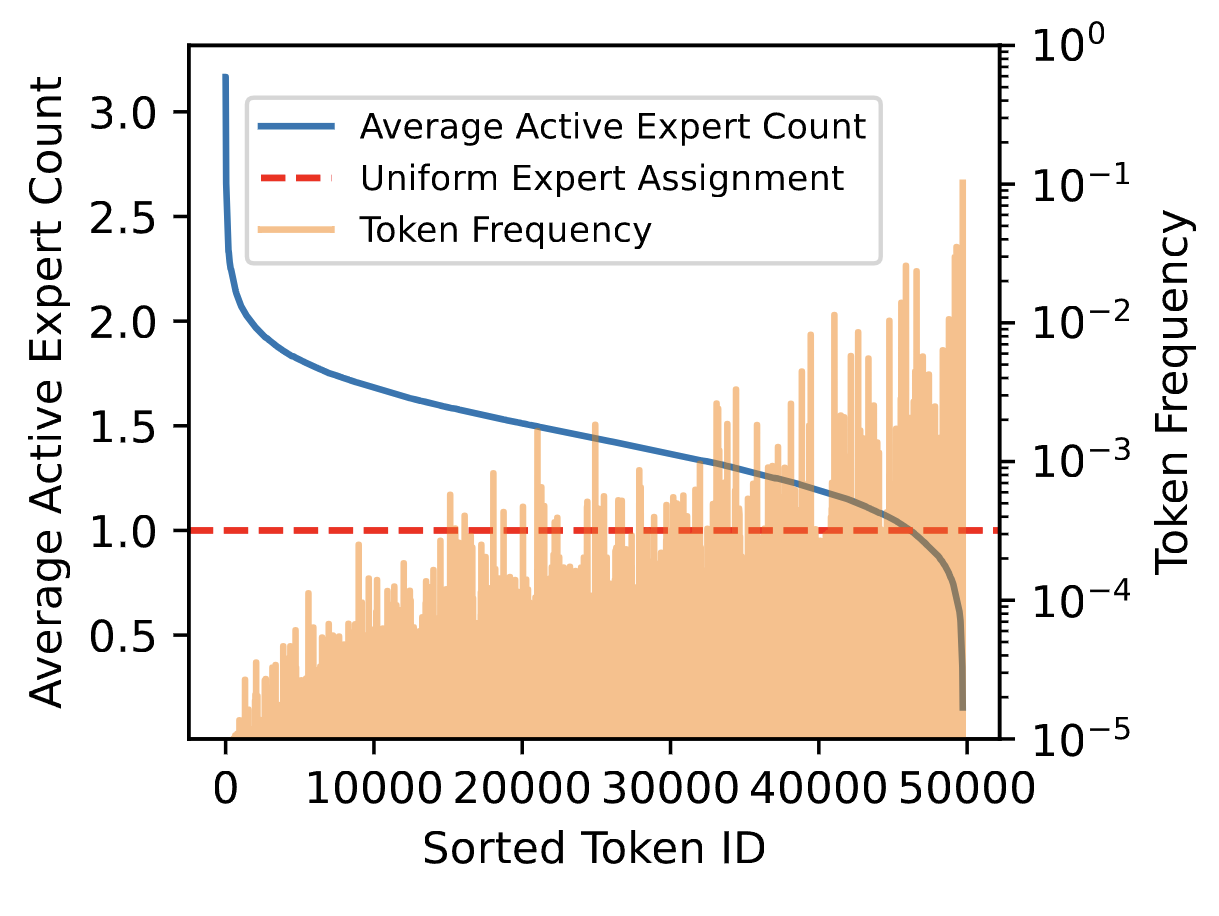
Authors claim that model dynamically allocates compute in prediction of common vs rare tokens.
Role of load balancing
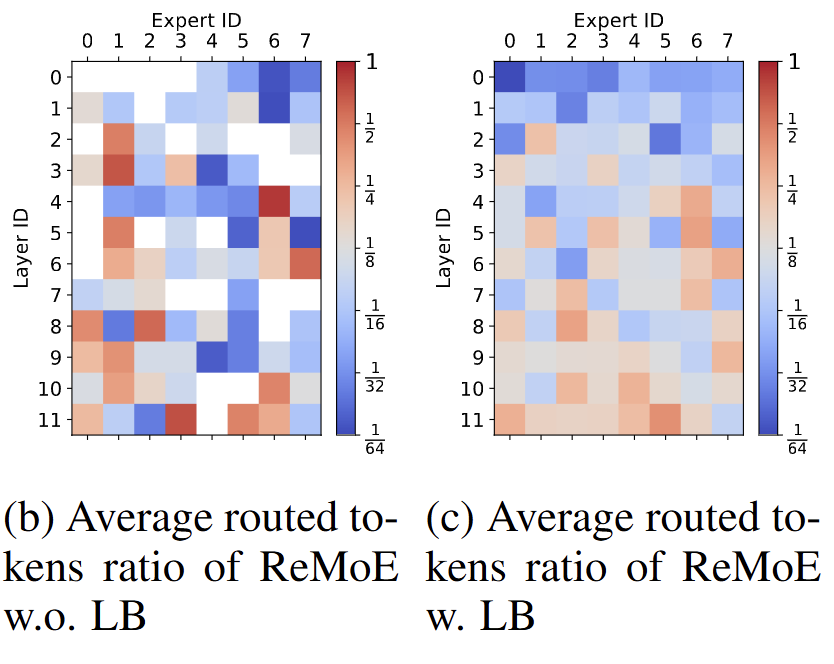
The white boxes are the experts which were activated with fewer than tokens. It’s interesting how very few experts are needed in the earlier layers when compared to the later layers.
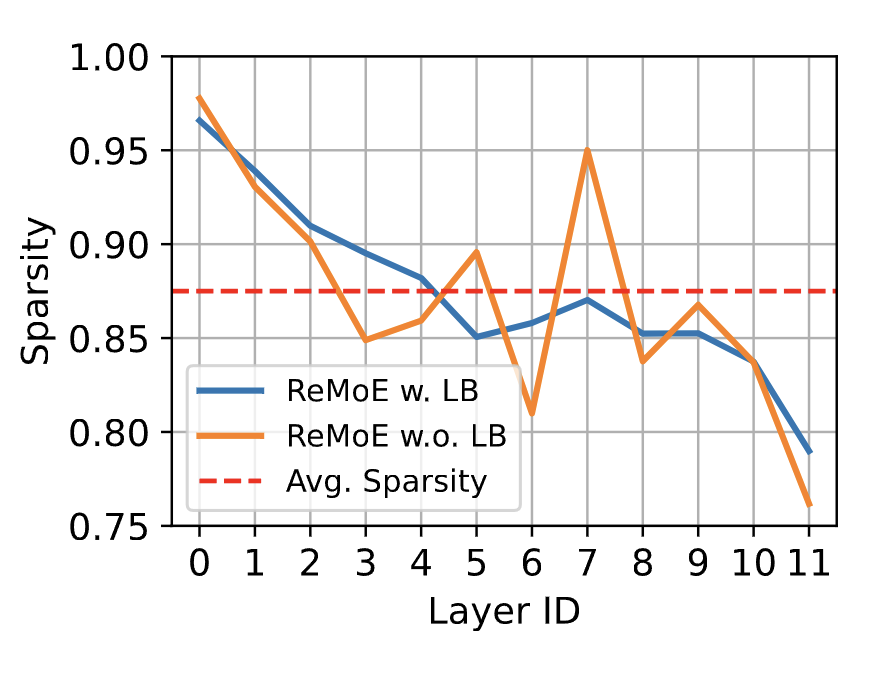
Average sparsity is around the desired level but earlier layers are so sparse when compared to later layers.
Domain specialised experts
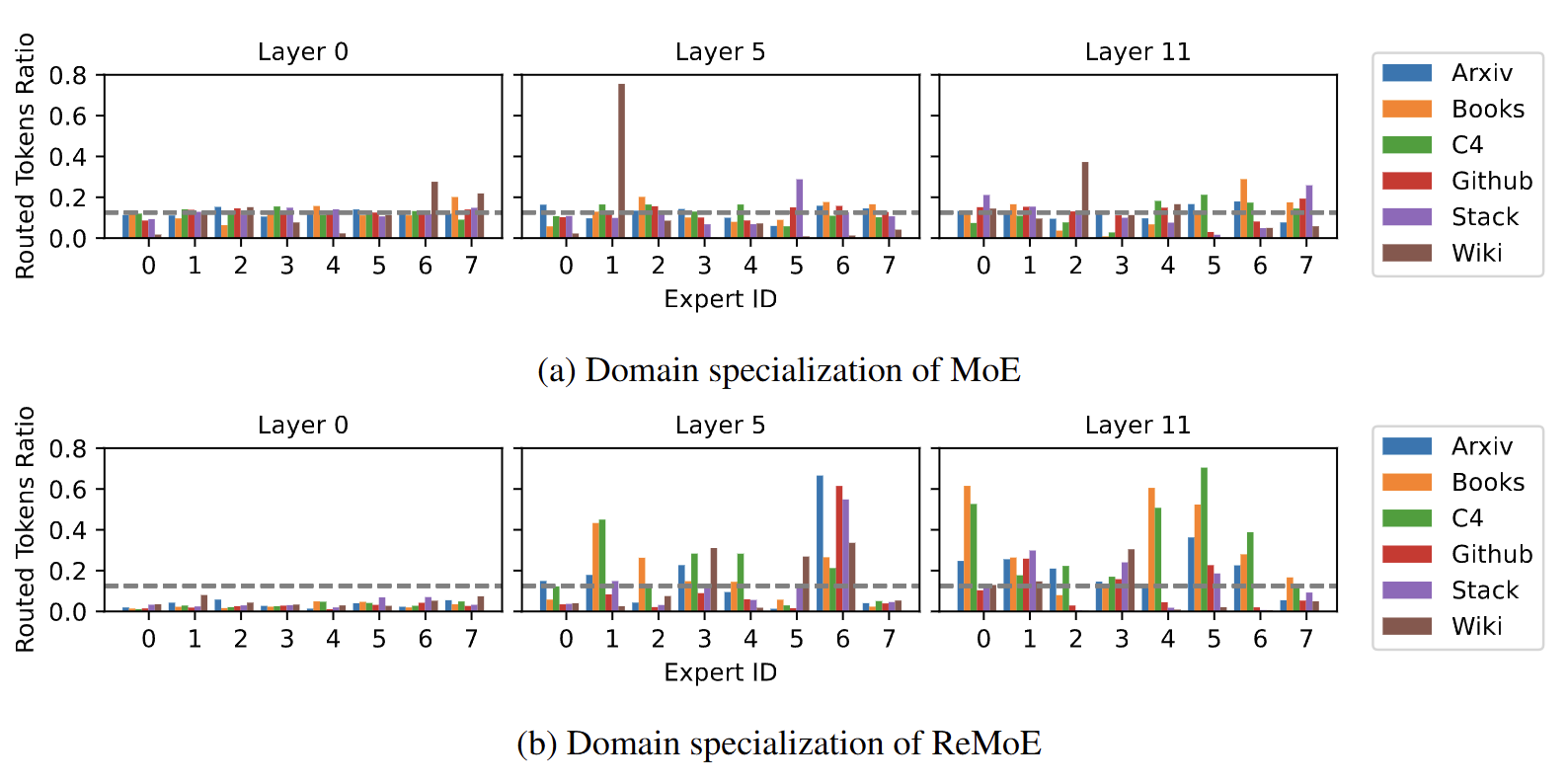
Also the experts are specialised when compared to regular