Paper: arXiv
Authors: Yueyang Cang, Yuhang Liu, Xiaoteng Zhang, Erlu Zhao, Shi Li
Date of Publication: 29th January 2025
Overview
This paper introduces a new transformer architecture based on differential transformer. Authors claim that a major drawback of differential transformer is that it’s rows of attention matrix aren’t normalised (they don’t sum up to one) so it causes numerical stability. And also authors claim that differential transformer lack global context modeling (they don’t explain why or how, they just declare it). To solve these issues they come up with a new architecture involving an ‘integration’ mechanism that apparently fixes this.
Differential Attention
The original differential transformer is a very good paper (must read, I’ll maybe make a post and link it here in future). I’ll briefly recap the architecture here. The authors of that paper introduce the differential attention mechanism. Authors calculate 2 attention matrices instead of one, and subtract one attention activation matrix from another (they take the difference, hence the name differential transformer). The authors came up with this as a way to reduce noise in the attention matrix. Intention was that, by allowing the model directly to subtract an attention matrix from another, it can learn to subtract the unnecessary noise. It was pretty popular at the time.
Specifically, given , it is projected to ,, matrices as usual. But,
We get 2 query matrices, 2 key matrices. We calculate 2 different attention matrices.
are learnable vectors and is a constant used for initialization.
Differential Transformer is a good paper.
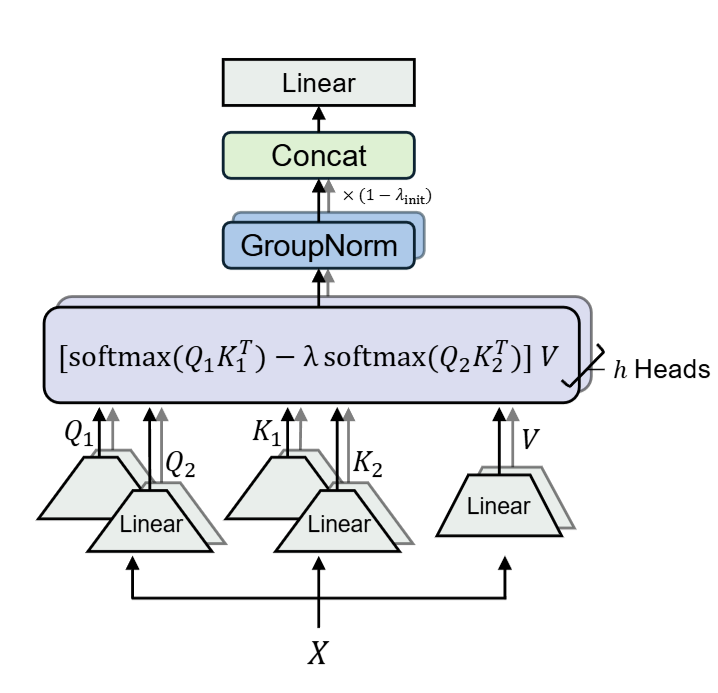
Group Norm is done along with layer norm too (I’ll go a bit in depth later while explaining DINT). A fixed multiplier is used after GroupNorm, which aligns the gradient flow with Transformer. And then there’s a linear layer after multi-head Differential Attention to project back to
DINT Attention
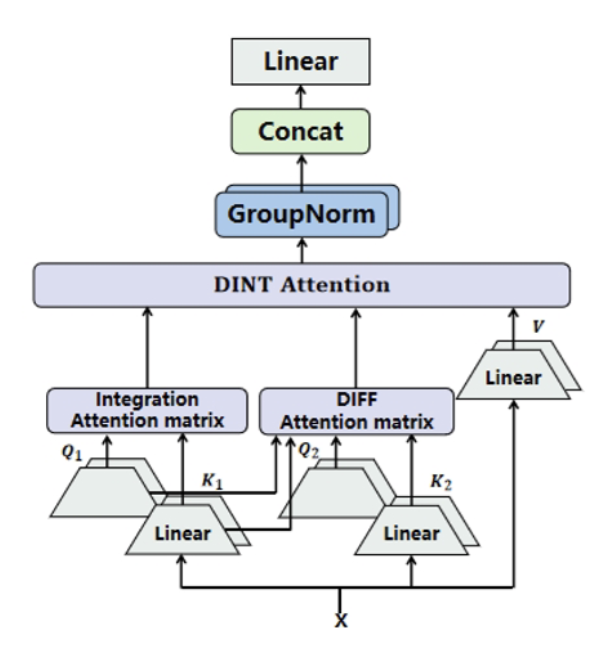
We had differential attention with no differential equations. Now we have differential integral attention with neither differential equations nor integration.
DintAttn Algorithm
In DINT, we calculate the two attention matrices of Differential Attention as usual. Let’s call them and
The ‘integral’ component of DINT computes the average attention scores of ‘s columns.
Essentially , where each element is the average value of each of the columns of
We just repeat the row vector , times and stack to create .
We set as . And if , the rows are normalised and sum up to 1.
I’m being honest, I don’t get why this works, but it just works, and the rows are normalised and sum upto 1. I have checked it numerically.
The authors claim that captures the global important features.
Multi-head DINT Attention
where, is shared between all the heads (that is the case in differential attention too).
is a learnable projection matrix.
uses RMS Norm for each head.
Even after headwise normalization, there is a group norm for more stable training.
def DintAttn(X, W_q, W_k, W_v, λ):
Q1, Q2 = split(X x W_q)// Split matrix multiplication result for QueriesK1, K2 = split(X x W_k)// Split matrix multiplication result for Keys (Corrected to W_k)V = X x W_v// Calculate Value matrixs = 1 / sqrt(d)// Scaling factorA1 = softmax((Q1 x K1.transpose(-1, -2)) x s)// Attention weights 1A2 = softmax((Q2 x K2.transpose(-1, -2)) x s)// Attention weights 2A3 = repeat(average(A1, column), n)// Average Attention (n is the number of rows in X)- return
(λ * A3 + A1 - λ * A2) x V// Final Attention Output
def MultiHeadDINT(X, W_q, W_k, W_v, W_o, λ):
-
Initialize an empty list
O// For outputs of each head -
for
i = 1toh: // Iterate through heads- Get the i-th slice of weight matrices:
W_qi,W_ki,W_vi// Slicing for the i-th head O_i = GroupNorm(DintAttn(X, W_qi, W_ki, W_vi, λ))// Differential Attention for i-th head- Append
O_ito listO
- Get the i-th slice of weight matrices:
-
return
Concat(O) x W_o// Concatenate head outputs and multiply by output weight
DINT Transformer Layer
Pretty standard transformer decoder layer. We use RMS norm instead of Layer Norm. SwiGLU is used as activation function and of course there’s DINT attention.
Results
As per authors this new architecture beats Differential Transformer in every single benchmark. They test on context based tasks like needle in a haystack, in-context learning, summarization, question answering. They evaluate the scalability, they compare loss of DINT with Differential Transformer as parameters and tokens are scaled. They analyse attention matrices.
Pretty much in every single metric it beats differential transformer. Read the paper for specific details.