Paper: arXiv
Authors: Jack Lanchantin, Angelica Chen, Shehzaad Dhuliawala, Ping Yu, Jason Weston, Sainbayar Sukhbaatar, Ilia Kulikov
Date of Publication: 31st January 2025
Overview
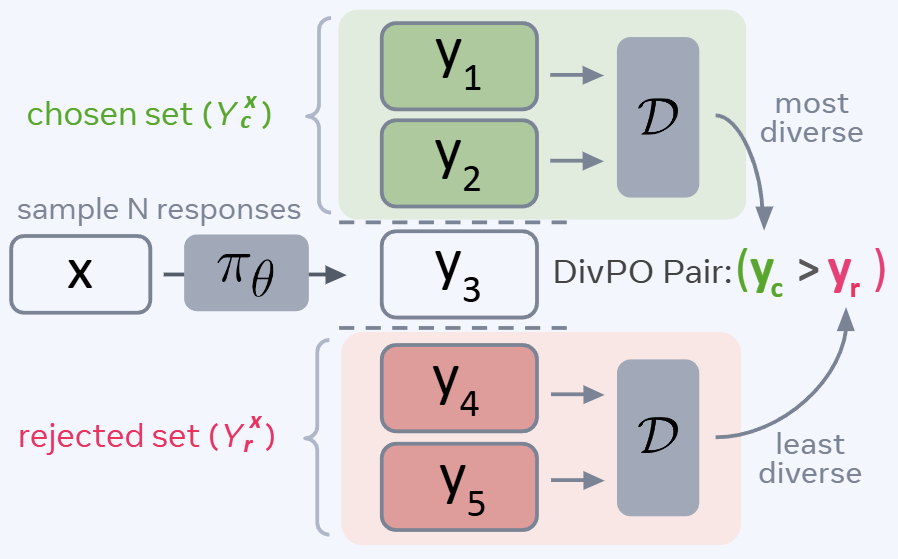
Authors propose Diverse Preference Optimization (DivPO), an optimization method to use during instruction tuning. In DPO we just use the highest rated response as positive sample and lowest rated response as negative sample. But in DivPO, authors choose multiple positive responses whose rewards are within a threshold of highest rated response and negative responses whose rewards are within a certain threshold from the most negative rated response. Once we have these two sets of positive and negative responses, they define a diversity criteria. Based on the diversity criteria they pick the most diverse response as positive response, and least diverse response as negative response. Once we have a preference pair, authors do RL using the pair.
Problem with methods like DPO in RLHF
During pre-training models are trained on a diverse set of corpora and models learn a probability distribution matching such data. However during RLHF, models are incentivised to maximise the cumulative reward obtained, and the original learned distribution from pre-training distribution collapses.
Models are optimized to minimise the above lose. Putting all sequence-level probability mass on the highest reward point is an optimal solution to this loss Even if multiple generations have the same reward, shifting all probability to only one of them is an optimal solution. Therefore, the objective of optimizing the cumulative reward causes collapse.
To prevent such collapse, a KL divergence term is added to the loss.
However, this still doesn’t show a way in increasing the diversity of responses by LLMs. Furthermore, LLMs are usually evaluated on quality of their responses (how correct they are) and not on diversity. Since LLMs are now used to generate synthetic data, lack of diversity leads to bias in next generation of models and can lead to significant downstream consequences.
Method to Increase Diversity
In DPO, the response with highest and the lowest rewards are chosen as a preference pair. But in DivPO, a set of positive responses and a set of negative responses are chosen. From the sets, the most diverse positive response and negative response are chosen for preference pair creation (irrespective of their reward values).
Authors define a hyper-parameter reward threshold, . All responses that have a reward value within percentage below the highest reward will be added to the chosen set. And all responses that have a reward value within percentage above the lowest reward will be added to the rejected set.
To define diversity, authors make use of 3 various ways:
-
Model Probability: If a particular response has a high probability to be generated, that means it’s more likely to be generated again. So authors define diversity as . The less likely responses are considered more diverse.
-
Word frequency: Given a set of responses, we can measure the frequencies of the words. A response with more frequent words is more likely to occur and would have a less diversity score.
-
LLM-as-a-Diversity-Judge: Authors use LLMs to get a score for diversity similar to how rewards are obtained.
Algorithm 1: DivPO Preference Pair Creation
Require: Training set , diversity criterion , reward threshold , base model , reward model ,
for prompt in :
- Sample responses:
- Score each response:
- Determine chosen set and rejected set based on reward values and threshold .
- Use diversity criterion to find most diverse from the chosen set: . Use diversity criterion to find least diverse from the rejected set: .
- Add to set of preference pairs
end for
Authors optimize the following loss function:
Pretty straight forward RLHF.
Experiments
Authors perform 3 experiments. In all the experiments Llama-3.1-8B-Instruct was used.
- Authors ask model to generate a persona for a character by specifying 5 particular characteristics in JSON format. All the responses with improper JSON structure are considered as responses with 0 reward and responses with correct JSON structure are considered as positive responses. Authors use frequency count as diversity metric.
- Given a title for a story, authors ask model to generate 5 keywords using which story can be written. Responses with greater or lesser than 5 words are considered as negative responses and responses with exactly 5 responses are considered as positive responses.
- Authors ask the model to write a story with the given title and 5 keywords around which story must revolve. Authors use a dedicated reward model for this task.
There are nuances, and I’m not fully explaining them here. Read the experiments section from the paper if you are particularly interested about little details.
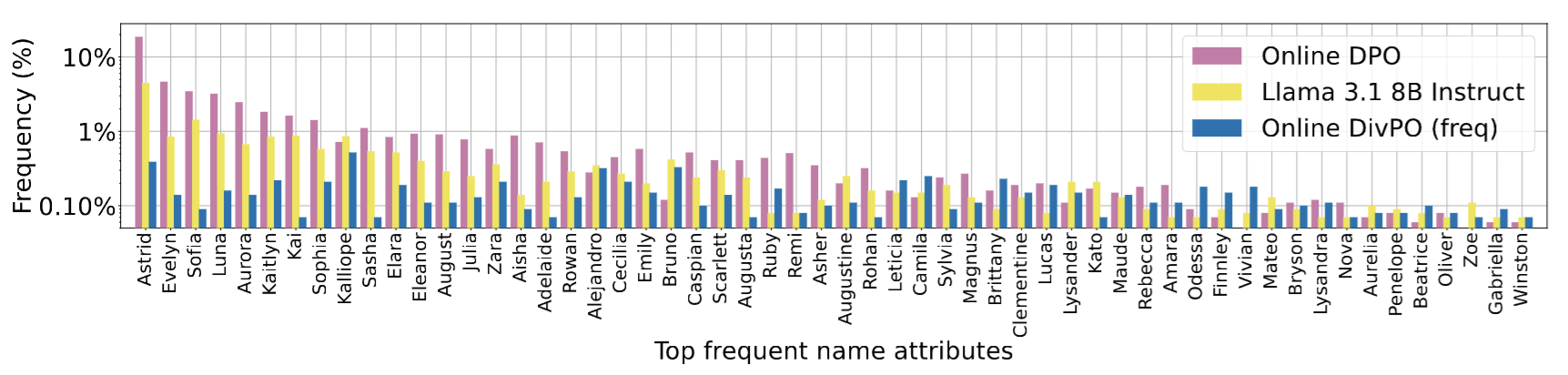
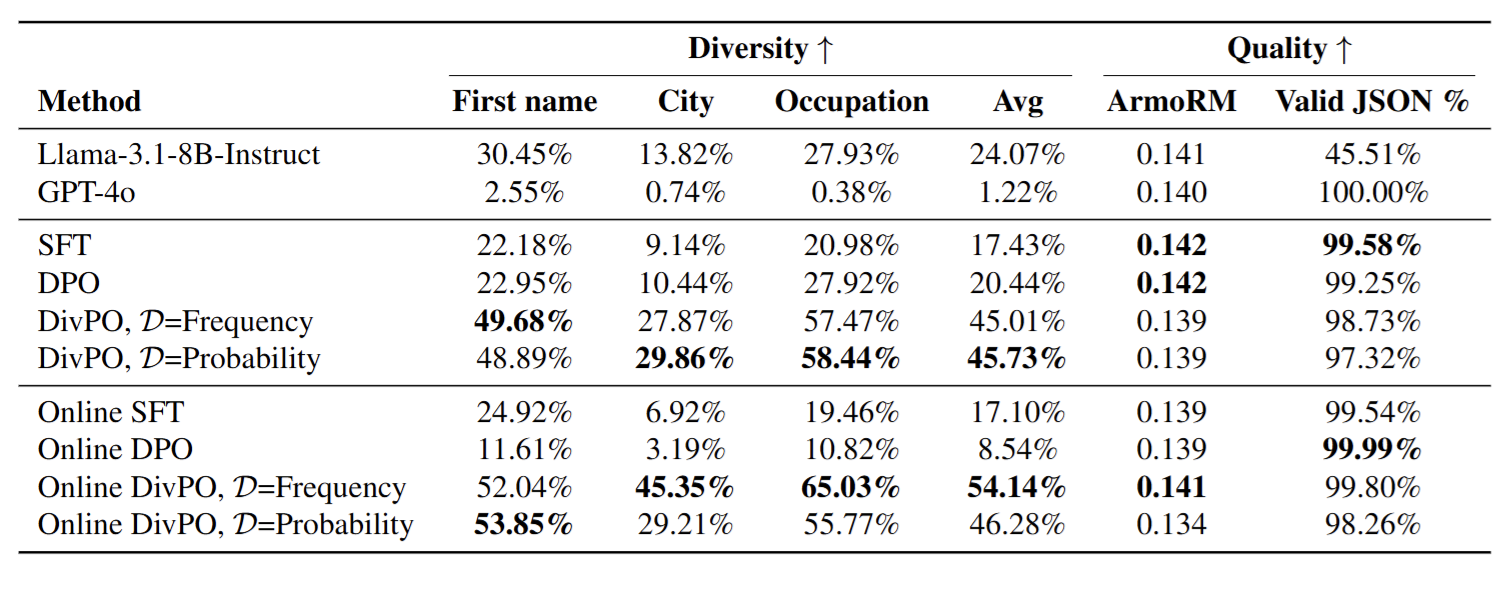
Thoughts
It works a bit better than other methods in generating diverse outputs, yeah. This makes the distribution of answers just a bit more spread out. We can’t use these as ‘random number generators’ as fundamentally they are trained to predict the next most probable token and eliminate all randomness. As long as we are in the autoregressive paradigm, we will not have much diversity. We can have these kinds of ‘patches’, but they don’t fix the underlying issue.