Paper: arXiv
Authors: Jihoon Tack, Jack Lanchantin, Jane Yu, Andrew Cohen, Ilia Kulikov, Janice Lan, Shibo Hao, Yuandong Tian, Jason Weston, Xian Li
Date of Publication: 12th February 2025
Overview
This paper introduces CoCoMix, a novel LLM pretraining method that leverages continuous concepts for improved performance and interpretability. The core methodology involves using pre-trained sparse auto-encoder (SAE) to decompose hidden states of the LLM being trained into a high-dimensional concept space. Importantly, CoCoMix then identifies the most relevant concepts for predicting the next token using ‘attribution scores’, predicting these selected concepts from the LLM’s residual activations, and finally, integrating these predicted concepts back into the model’s residual stream.
Preliminaries
Let be the residual activation of transformer at position .
is the dimension of residual stream.
Sparse auto-encoder (SAE)
A sparse auto-encoder projects the residual activations of a transformer at a particular layer into much higher dimensional concept space. When applied to an LLM, the SAE decomposes the hidden state into multiple dimensions, each of which can be viewed as a distinct concept capturing semantically meaningful features. There is a sparsity constraint enforced on the concept space.
Let be the encoder of SAE, where is the dimension of concept space .
Let be the decoder of SAE.
The reconstruction process of SAE is:
where is pre-activation function concept vector in the concept space.
where TopK is the activation function (they used TopK in this paper, commonly Jumpy ReLUs are also used amongst many other). TopK zeros out all but top K entries. Intuitively, the remaining K entries each can be viewed as representations of distinct concepts.
where is the reconstructed residual activation.
SAE is trained by minimizing the reconstruction loss: . By
enforcing TopK sparsity, the SAE isolates the most critical dimensions in that explain the pretrained model’s features.
Continuous Concept Mixing
Continuous Concept Mixing involves 2 major steps:
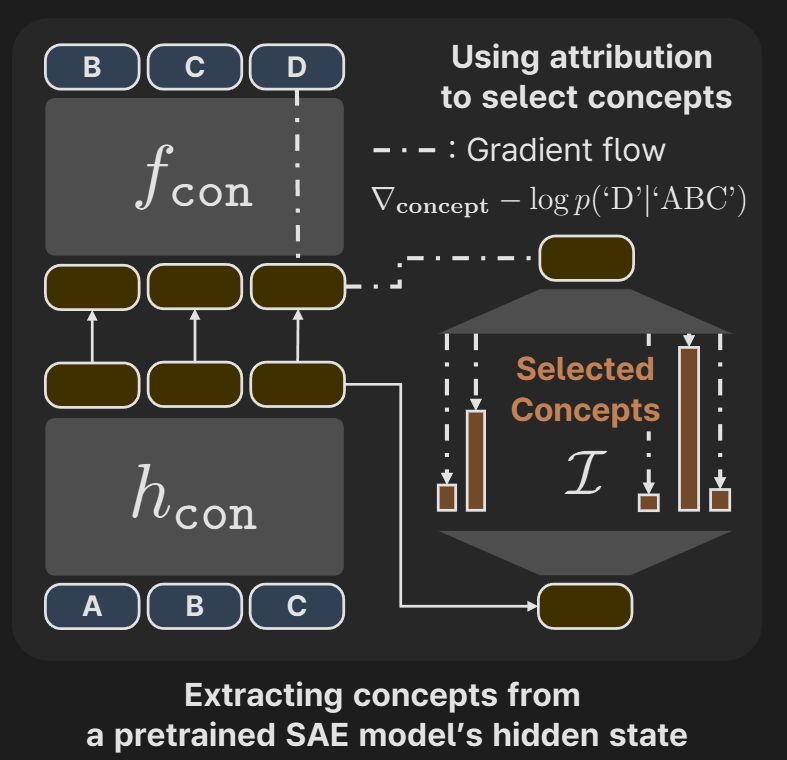
- Using a pre-trained SAE of some other model, architecture involves selecting the most important concepts from the SAE concept space.
- Residual stream activations of the model being trained are used to predict the selected concepts from the SAE. The predictions are concatenated to the residual activations and the forward pass continues as usual.
Selecting Important Target Concepts using Attribution Score
While the extracted concepts by SAE represent the core concepts, they may not be useful in predicting the next token. To select the important concepts that help in predicting the next token, authors use attribution.
Let represent the entire LLM after the point of . That is, let the entire LLM be . Then, .
Authors define attribution score by:
Remember that was the concept activation vector after the TopK activation function. represents the change in loss (in predicting the next token) with respect to . Intuitively, the elements in the gradient vector are large if that particular concept is important, else they are small.
We element-wise multiply the gradient with to obtain the attribution scores. Note that we are multiplying with to also capture the concepts that would have been missed due to TopK. Remember that
Next they select the top values of . Based on the indices of the top values, authors form one-hot vectors denoted by , they may not exactly be ‘one-hot’, instead of ‘1’ they were maybe using the score [Disclaimer: Authors don’t explain this part properly in the paper and a lot of details are omitted, I filled in with my best guesses]. These are the targets that the LLM being trained on needs to predict. The
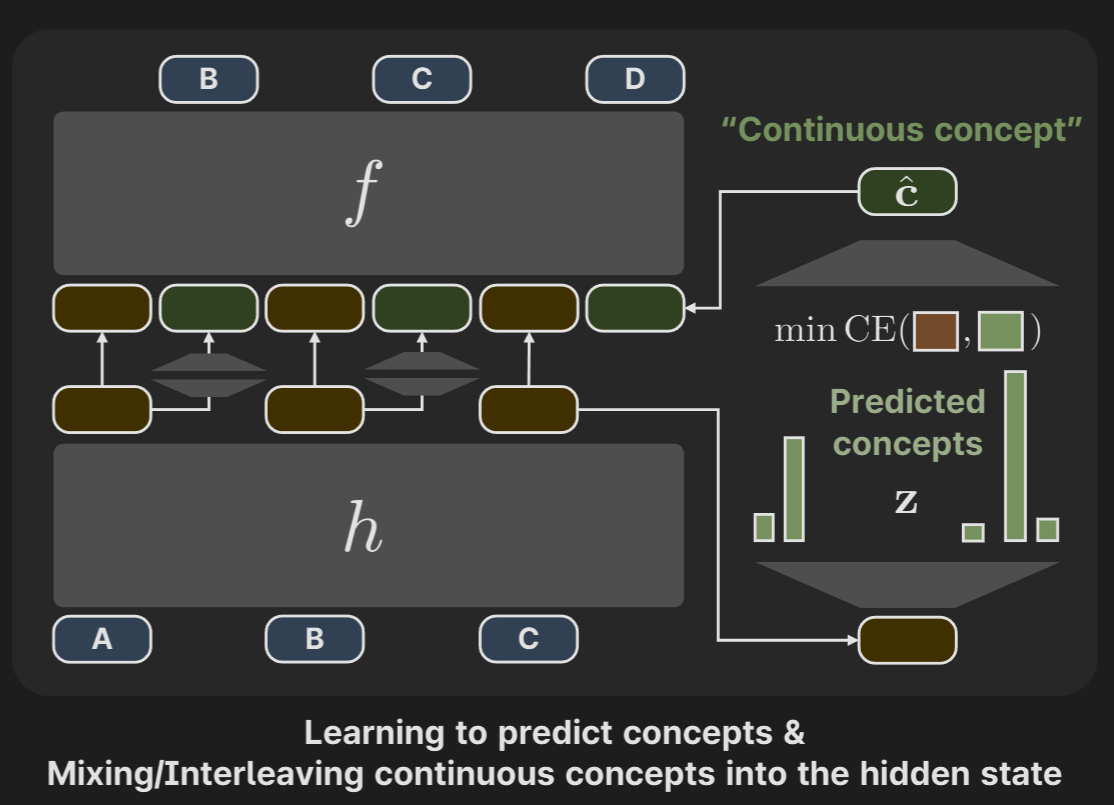
Predicting the selected concepts
Using the residual activations of the LLM, is projected by .
The concept loss is defined as:
Authors don’t mention this clearly in the paper, but it looks like a single prediction is made for all the target one-hot vectors in .
Mixing continuous concepts with token embeddings
The prediction that was made previously is projected back to :
is the ‘continuous concept’. They again used TopK when projecting back in the reverse direction too (from concept space to residual activation space).
Intuitively, we are trying to identify the important concepts and use them for next token prediction. Residual activation was projected to the Concept space, important concepts (that were identified using pre-trained SAE and attribution scores) were predicted, and then it was projected back to the regular activation space. There’s an implicit bias that a given token only uses a few number of concepts, so there’s sparse constraint of TopK.
The ‘continuous concept’ is concatenated with the residual activation. So the residual stream of the model looks like .
This design improves performance and also the predicted concepts can be used to steer the model’s generation process and can be used in alignment.
Training objective
Next token prediction loss along with the concept prediction loss. is a hyperparameter.
Authors train 3 models of 69M, 386M and 1.38B sizes. The concept prediction is done at the 4th layer for the 69M model and the 6th layer for the larger 386M and 1.38B models. They used SAE of trained on the 6th layer of 124M parameter GPT-2.
Interpretability and Steerability of CoCoMix
To verify if actually captures concepts, they multiply the vector by constants ranging from -10 to 10. They also do the same in the pre-trained model from which this SAE comes from (i.e. GPT-2 124M).
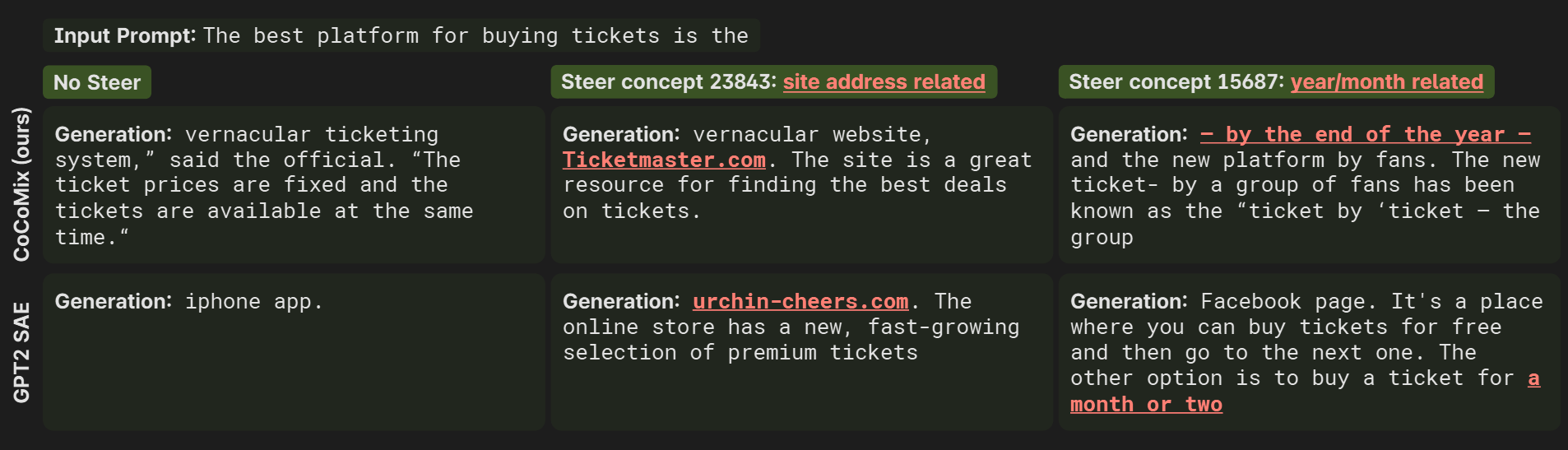
It works!
Results
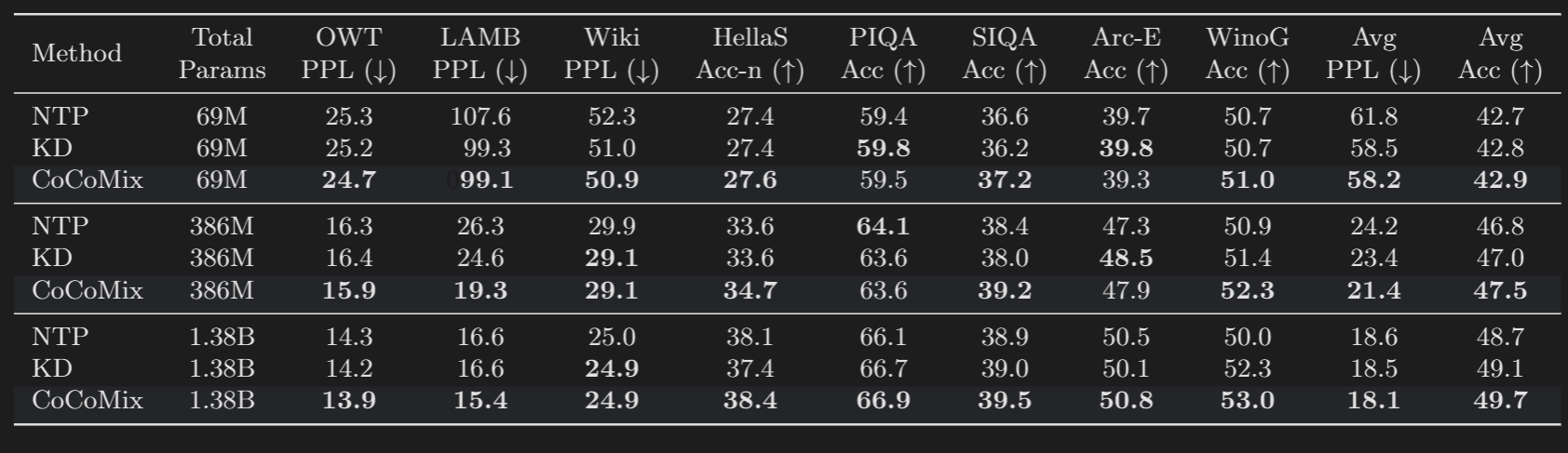
CoCoMix is the architecture of this paper, KD is a model trained on Knowledge Distillation (only with KL divergence between teacher and student as loss), and NTP is a simple decoder only transformer. 124M GPT-2 was used as a teacher-model in all the cases, to keep comparisons fair. CoCoMix slightly beats KD.
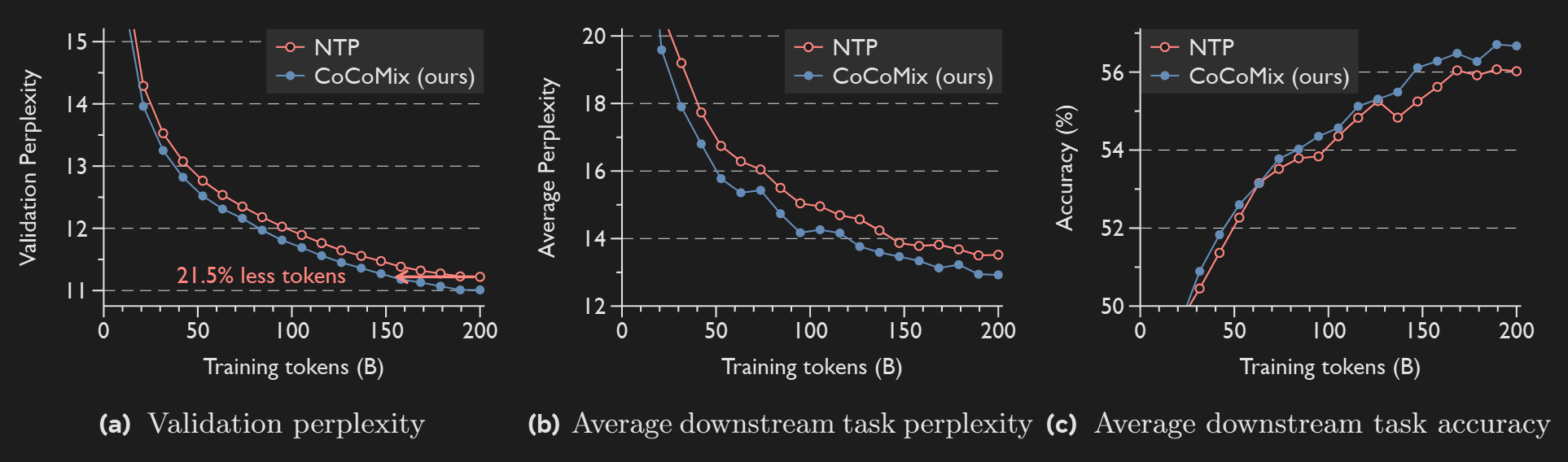
CoCoMix takes 21.5% less tokens when compared to regular decoder-only model to achieve same performance.
There are a lot more experiments done. Check out the paper if you need the details.
Thoughts
A pretty interesting idea. Why distill the knowledge when you can directly ‘suck’ it straight from the concept space.
Implementing this requires so much engineering effort. First we need to obtain a sparse auto encoder of a model whose residual dimension size must be the same as the residual dimension of the model being trained, so that the dimensions match.