Paper: arXiv
Authors: Anton Razzhigaev, Matvey Mikhalchuk, Temurbek Rahmatullaev, Elizaveta Goncharova, Polina Druzhinina, Ivan Oseledets, Andrey Kuznetsov
Date of Publication: 20th February 2025
Repository: GitHub
Overview
In this paper authors introduce a toolkit called LLM microscope. The tool kit can be used for the following tasks: token-level non-linearities, contextualization assessment, intermediate layer prediction assessment, logit lens and intrinsic Dimension of Representations. I’ll briefly breakdown what these terms mean. LLM microscope is available as a pip package to use.
Using the toolkit they also perform few small experiments using which authors infer that LLMs use punctuations, stop-words to store summaries of the prefix tokens.
Measuring Token-Level Non-linearity
and are the normalized and centered (with zero-mean) matrices of the token embedding in the layer and respectively. is the optimal linear transformation of the embedding from layer to layer .
denotes the Frobenius norm. For a matrix it is defined as follows:
The non-linearity score for each token at layer would be:
where represents the embedding of token at layer .
Assessing Contextual Memory in Token-Level Representations
To measure the ability of tokens to reconstruct its prefixes, authors introduce this method.
- Authors first process the sequence through the LLM and they collect hidden states for each token across all layers.
- For every token, they use a trainable linear pooling layer to combine the embeddings from all the layers into a single embedding. So now they have a single embedding for each token. They pass that through a 2 layer MLP.
- The resultant embedding is used as input to another copy of the original model which attempts to reconstruct the prefix to the chosen token.
They train the linear pooling, MLP and the copy of the model on few small datasets.
The Contextual Memory score is given by
where is the probability of the true prefix given the embedding .
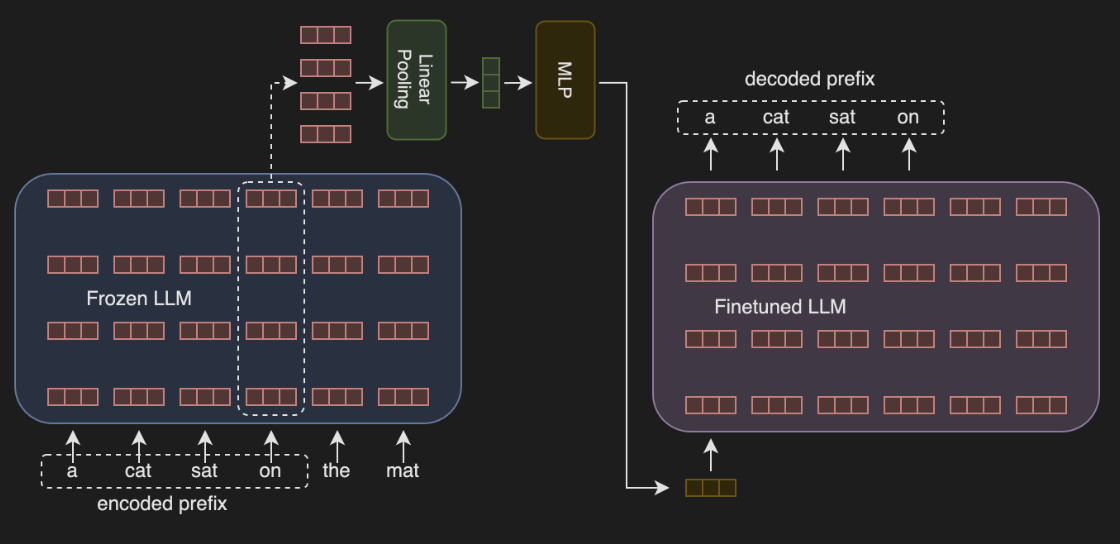
Examining Intermediate Layers Contribution to Token Prediction
They use the LM head (i.e. the linear layer that projects the final embedding into logits) at each intermediate layer for each token to get the probability distribution over vocabulary, and calculate the loss of predicting the true token.
More formally, let be the probabilities over vocabulary at token and layer .
gives the prediction loss where is the true next token.
This allows us to examine the prediction loss and how it evolves across all the layers.
Visualizing Intermediate Layer Predictions
This is nothing but the logit lens. Authors take the embedding at layer and token and project it to vocabulary using the LM head, and they provide tools to visualise it. The standard logit lens.
Intrinsic Dimension of Representations
I didn’t understand this, I’ll get back to it later again and edit this section. This was originally proposed in the paper by Facco et al..
This was the explanation provided by authors in this paper:
This approach examines how the volume of an n-dimensional sphere (representing the number of embeddings) scales with dimension . For each token embedding, we compute:
where and are the distances to the two nearest neighbors. This intinsic dimension is then estimated using:
where is the cumulative distribution function of .
Experiments
Using these tools, authors perform few experiments
The Most Memory Retentive Tokens
To analyse how different types of tokens contextualise the information of it’s preceding tokens, authors collect the contextualization scores as described above. They use a few wikipedia articles for this task.
They find that punctuation marks have the highest Contextualisation score . It should not be that surprising since we have known this since years now that LLMs use punctuation marks as a way to summarise the sentences and store information. LLMs can attend to the punctuation marks instead of the whole sentence and get a summary of it, whenever needed further down the line.
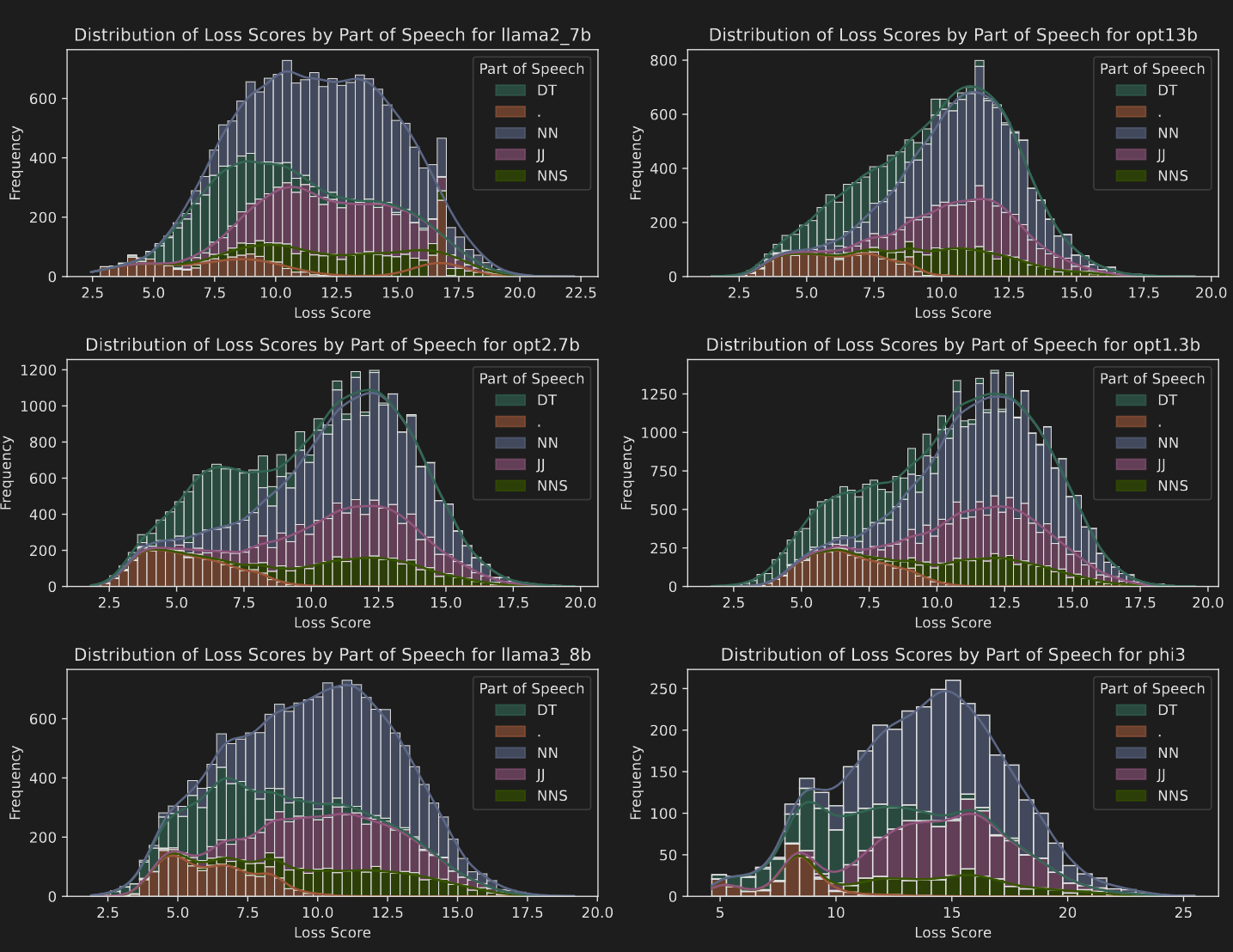
‘DT’ in the graph represents determiners, ‘NN’ and ‘NNS’ represents Nouns. ’.’ represents punctuations. The loss is quite low for punctuations, meaning it’s easier to predict the prefix tokens of punctuations.
Examining the Impact of Removing “Filler” Tokens
They remove the filler tokens like punctuations, stop-words and examine the performance degradation on two tasks, MMLU and BABILong-4k. A human should not a huge problem in these tasks when stop-words and punctuations are removed, but we see some degradation in performance in LLMs.
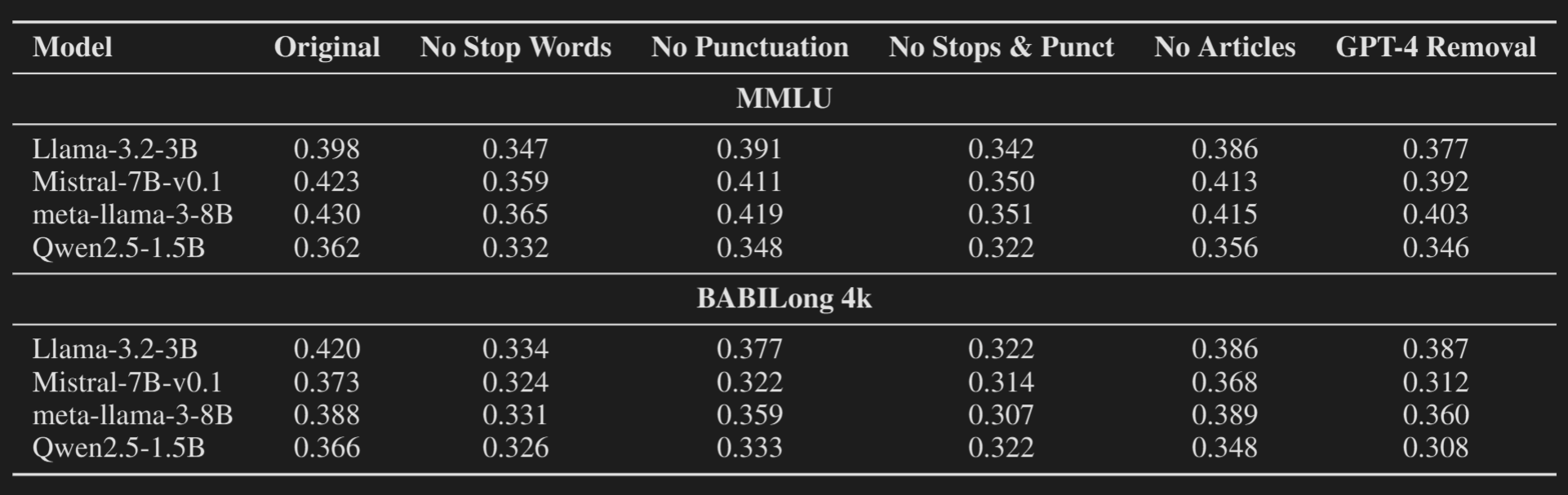
In the GPT-4 column, they remove the filler words which were suggested by GPT-4o, whose removal does not break the sentence and change the meaning of the sentence significantly.
I am quite surprised by how little the performance degradation is, especially on MMLU. I expected we’d see a lot more degradation. But also, it makes sense. MMLU is quite easy to do, and we don’t need to contextualise previous information on punctuations.
Performance degradation on BABILong-4k is quite significant. It tests long context understanding, and we do need the mechanism to summarise previous tokens at punctuations so that it’s easier to attend to them later.
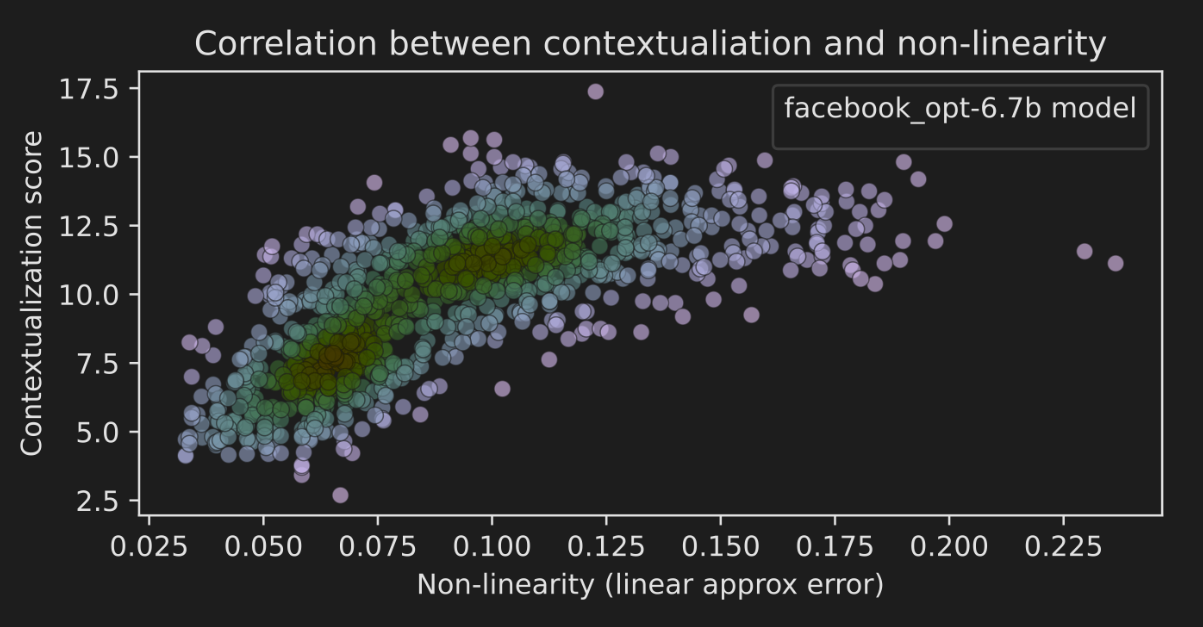
Correlation Between Non-linearity and Context Memory
They observed a significant correlation between layer-averaged non-linearity scores and contextualization scores for individual tokens. Tokens with high contextualization tend to correspond to the most non-linear transformations across layers.
Apart from these experiments, they also do a small experiment with logit lens. That was not novel and was done hundreds of times.
Thoughts
Seems a pretty simple paper. Nothing fancy. But I have always heard that LLMs summarise sentences at full-stops, but I never actually read any experiments which showed the phenomenon. I got to see that in action in this paper, which was nice.
I am excited about their toolkit. These additional tools will be quite useful. I’ll play around with them.